HashMap的原理
JDK 1.7 中 HashMap 的数据结构是数组+链表
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
HashMap 使用键的 hashCode() 方法计算哈希值,并通过 indexFor 方法(JDK 1.7 及之后版本移除了这个方法,直接使用数组大小n(n - 1) & hash)确定元素在数组中的存储位置。哈希值是经过一定扰动处理的,防止哈希值分布不均匀,从而减少冲突。
HashMap 的默认初始容量为 16,负载因子为 0.75。也就是说,当存储的元素数量超过 16 × 0.75 = 12 个时,HashMap 会触发扩容操作,容量x2并重新分配元素位置。这种扩容是比较耗时的操作,频繁扩容会影响性能。
扩展点
HashMap 的红黑树优化:
从 Java 8 开始,为了优化当多个元素映射到同一个哈希桶(即发生哈希冲突)时的查找性能,当链表长度超过 8 时,链表会转变为红黑树。红黑树是一种自平衡二叉搜索树,能够将最坏情况下的查找复杂度从 O(n) 降低到 O(log n)。
如果树中元素的数量低于 6,红黑树会转换回链表,以减少不必要的树操作开销。
hashCode() 和 equals() 的重要性:
HashMap 的键必须实现 hashCode() 和 equals() 方法。hashCode() 用于计算哈希值,以决定键的存储位置,而 equals() 用于比较两个键是否相同。在 put 操作时,如果两个键的 hashCode() 相同,但 equals() 返回 false,则这两个键会被视为不同的键,存储在同一个桶的不同位置。
误用 hashCode() 和 equals() 会导致 HashMap 中的元素无法正常查找或插入。
默认容量与负载因子的选择:
默认容量是 16,负载因子为 0.75,这个组合是在性能和空间之间找到的平衡。较高的负载因子(如 1.0)会减少空间浪费,但增加了哈希冲突的概率;较低的负载因子则会增加空间开销,但减少哈希冲突。
哈希冲突链表法图解
在 JDK1.7 及之前链表的插入采用的是头插法,即每当发生哈希冲突时,新的节点总是插入到链表的头部,老节点依次向后移动,形成新的链表结构
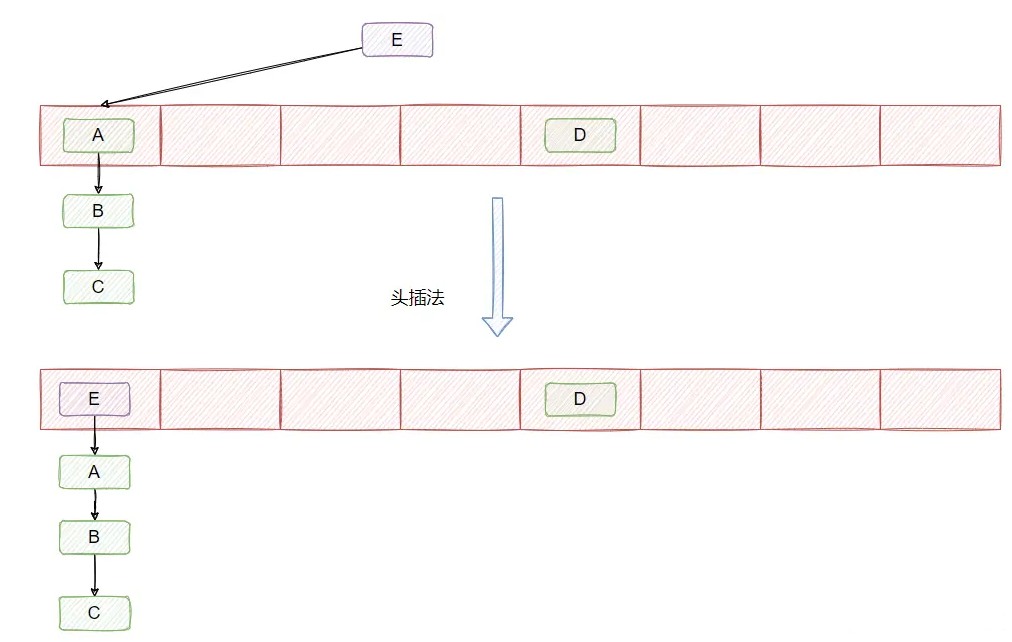
在多线程环境下,头插法可能导致链表形成环,特别是在并发扩容时(rehashing)。当多个线程同时执行 put() 操作时,如果线程 A 正在进行头插,线程 B 也在同一时刻操作链表,可能导致链表结构出现环路,从而引发死循环,最终导致程序卡死或无限循环。
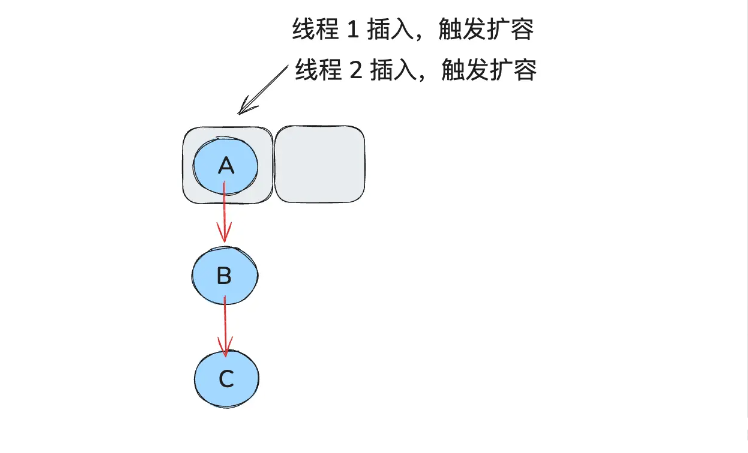
举个例子:
假如此时线程 1 和 2 同时在插入,同时触发了扩容:
/**
* 将所有 Entry 从当前表转移到 newTable。
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length; //新数组的容量
for (Entry<K,V> e : table) { // 遍历原 table 中的每个桶
while (null != e) { // //遍历table中的链表table[i]
Entry<K,V> next = e.next; //1线程在跑,2线程没有跑
// 重新计算 hash 值(rehash=true 的情况下)
if (rehash) {
e.hash = (null == e.key) ? 0 : hash(e.key);
}
// 计算在新数组中的索引
int i = indexFor(e.hash, newCapacity);
// 头插法,将当前元素插入到新的位置
e.next = newTable[i];
newTable[i] = e;
// 继续处理下一个节点
e = next;
}
}
}
假设此时,线程 1 中 e 是 A,next 为 B,刚要开始搬运,时间片到了,此时停止操作
而线程 2 开始扩容,且成功扩容完毕,此时:
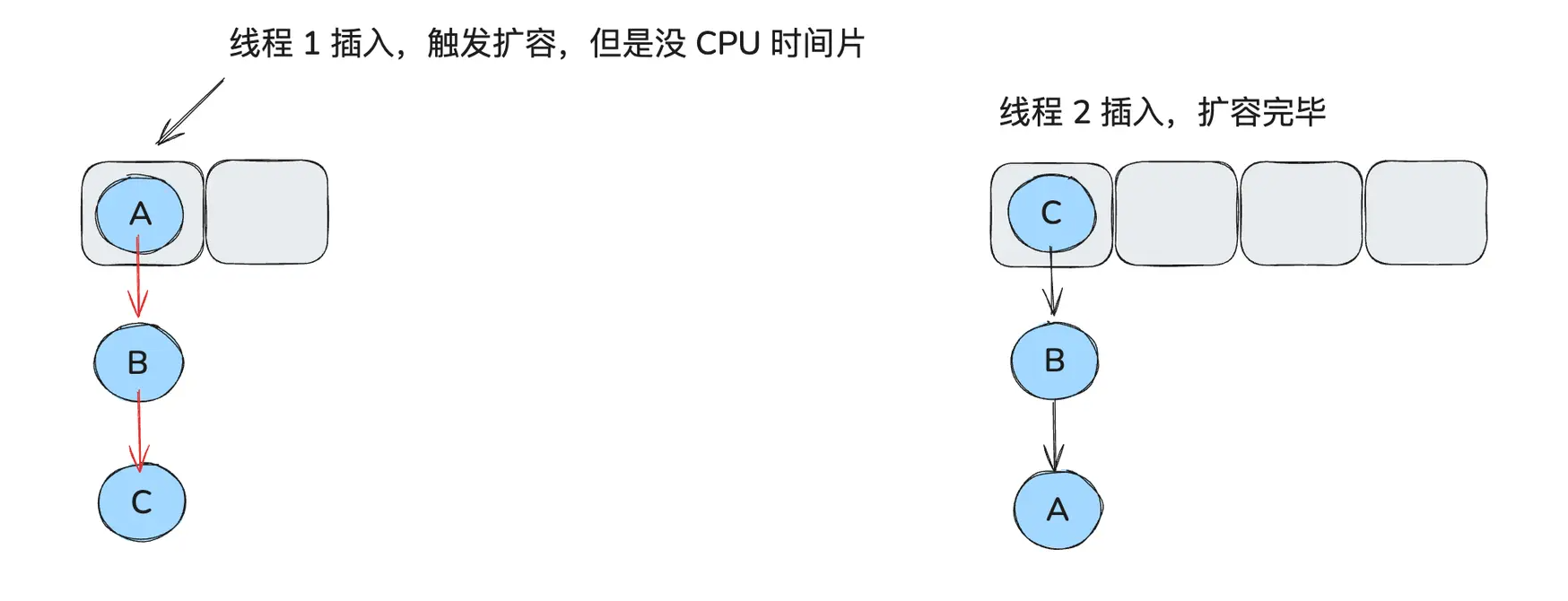
待线程 2 扩容完毕后,线程 1 得到了时间片要开始执行了,它开始执行以下代码:
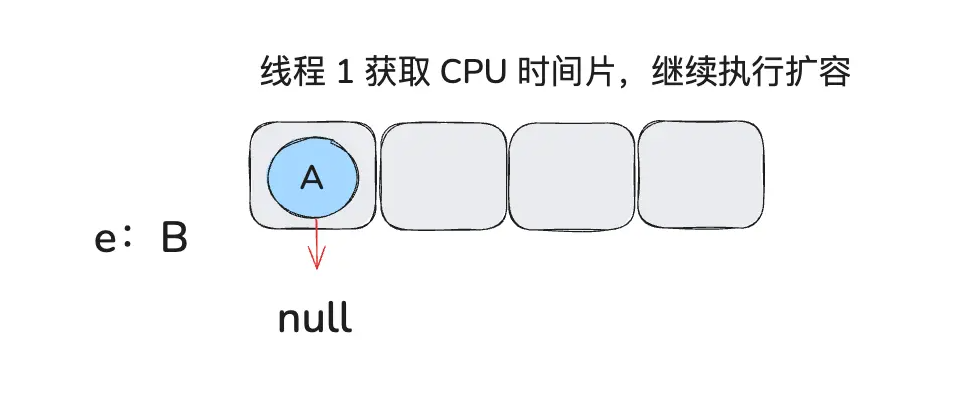
e.next = newTable[i]; // A.next = null
newTable[i] = e;
e = next;
此时 A.next = null,因为线程 1 的 newTable 是新建的,此时上面还没有数据,所以 A.next 为 null,且被放到数组上,e 变成 B。
do {
Entry<K,V> next = e.next; // e 为 B,e.next 为 A
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // B.next = A
newTable[i] = e; // newTable[i] = B
e = next; // e = A
} while (e != null);
由于线程 2 的操作,e.next 已经变成了 A,hashmap 变成如下结构:
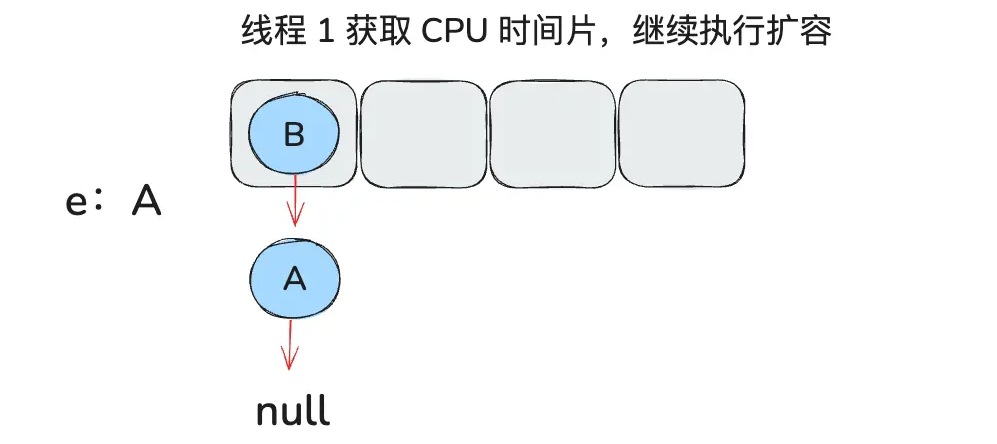
由于 e != null 继续循环执行以下代码
do {
Entry<K,V> next = e.next; // e 为 A,e.next 为 null
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // A.next = B
newTable[i] = e; // newTable[i] = A
e = next; // e = null
} while (e != null); // e ==null 跳出循环,此时成环。
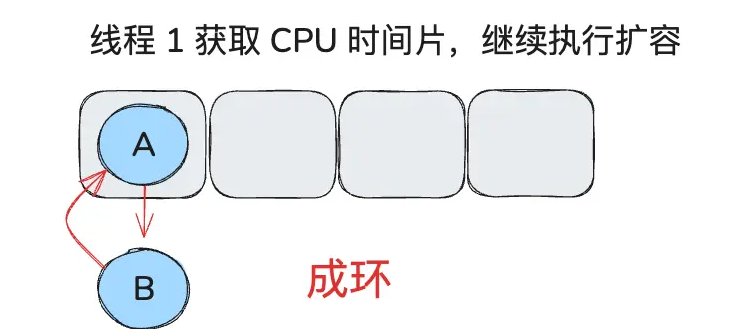
在 JDK1.8 的时候,改成了尾插法,即新的节点插入到链表的尾部,保持插入的顺序。并且引入了红黑树。
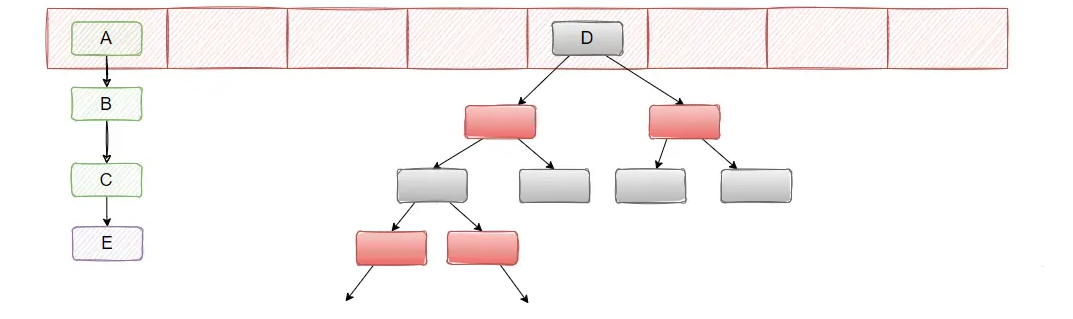
rehashing 细节
按照我们的思维,每一个元素应该是重新 hash 一个一个搬迁过去。
在 1.7 的时候就是这样实现的,然而 1.8 在这里做了优化,关键点就在于数组的长度是 2 的次方,且扩容为 2 倍。
因为数组的长度是 2 的 n 次方,所以假设以前的数组长度(16)二进制表示是 010000,那么新数组的长度(32)二进制表示是 100000,这个应该很好理解吧?
它们之间的差别就在于高位多了一个 1,而我们通过 key 的 hash 值定位其在数组位置所采用的方法是 (数组长度-1) & hash。我们还是拿 16 和 32 长度来举例:
16-1=15,二进制为 001111
32-1=31,二进制为 011111
所以重点就在 key 的 hash 值的从右往左数第五位是否是 1,如果是 1 说明需要搬迁到新位置,且新位置的下标就是原下标+16(原数组大小),如果是 0 说明吃不到新数组长度的高位,那就还是在原位置,不需要迁移。
所以,我们刚好拿老数组的长度(010000)来判断高位是否是 1,这里只有两种情况,要么是 1 要么是 0 。
每次扩容都需要遍历当前所有的元素,重新计算哈希值并移动它们到新的位置,因此扩容是一个比较耗时的操作。如果频繁扩容,整体性能会明显下降。
优化策略:如果能预估到 HashMap 中大概会存储多少数据,可以在创建 HashMap 时就指定一个较大的初始容量,以减少扩容次数。例如,对于存储 100 万个元素的 HashMap,可以直接设置一个 1024 × 1024 的初始容量,避免多次扩容。
场景题
为什么hashmap扩容要用&运算?
1、哈希分布均匀性
如果数组容量为 2 的 n 次方,那么 n - 1 后低位都是 1 ,此时进行 & (两个位都为 1 时,结果才为 1)运算可以确保哈希码的最低几位均匀分布。
比如 64 二进制表示为 0100 0000,64 - 1 = 0011 1111。
此时 0011 1111 与哈希码进行 & 运算,低位能均匀的反应出哈希码的随机性。
假设来个 0100 0000 与哈希码进行 & 运算,那么低位得到的值就都是 0 了,随机性很差,都是冲突。
2、位运算与取模
正常情况下,如果基于哈希码来计算数组下标,我们想到的都是 %(取余)计算。例如数组长度为 5 ,那么哈希码 % 5 得到的值就是对应的数组下标。
但相比于位运算而言,效率比较低,所以推荐用位运算,而要满足 i = (n - 1) & hash 这个公式,n 的大小就必须是 2 的 n 次幂。即:当 b 等于 2 的 n 次幂时,a % b 操作等于 a & ( b - 1 )
3、 计算新索引
HashMap 扩容时,元素需要从旧数组迁移到新数组。为了确定元素在新数组中的位置,通常使用 hash & (newCapacity - 1) 来计算索引。
JDK 1.8 对 HashMap 除了红黑树还进行了哪些改动?
- 改进了哈希函数的计算:1.7 的操作太多了,经历了四次异或,所以 1.8 优化了下,它将 key 的哈希码的高 16 位和低 16 位进行了异或,得到的 hash 值同时拥有了高位和低位的特性,使得哈希码的分布更均匀,不容易冲突。
- 扩容机制优化:JDK 1.8 改进了扩容时的元素迁移机制。在扩容过程中不再对每个元素重新计算哈希值,而是根据原数组长度的高位来判断元素是留在原位置,还是迁移到新数组中的新位置。这一改动减少了不必要的计算,提升了扩容效率。
- 头插法变为尾插法:头插法的好处就是插入的时候不需要遍历链表,直接替换成头结点,但是缺点是扩容的时候会逆序,而逆序在多线程操作下可能会出现环,产生死循环,于是改为尾插法。
hashmap,为什么线程不安全
扩容时环形链表,多线程put到同一个位置。
为什么 HashMap 在 Java 中扩容时采用 2 的 n 次方倍?
HashMap 采用 2 的 n 次方倍作为容量,主要是为了提高哈希值的分布均匀性和哈希计算的效率。
HashMap 通过 (n - 1) & hash 来计算元素存储的索引位置,这种位运算只有在数组容量是 2 的 n 次方时才能确保索引均匀分布。位运算的效率高于取模运算(hash % n),提高了哈希计算的速度。
且当 HashMap 扩容时,通过容量为 2 的 n 次方,扩容时只需通过简单的位运算判断是否需要迁移,这减少了重新计算哈希值的开销,提升了 rehash 的效率
Java 中 ConcurrentHashMap 1.7 和 1.8 之间有哪些区别
JDK 1.7 ConcurrentHashMap 采用的是分段锁,即每个 Segment 是独立的,可以并发访问不同的 Segment,默认是 16 个 Segment,所以最多有 16 个线程可以并发执行。
而 JDK 1.8 移除了 Segment,锁的粒度变得更加细化,锁只在链表或红黑树的节点级别上进行。通过 CAS 进行插入操作,只有在更新链表或红黑树时才使用 synchronized,并且只锁住链表或树的头节点,进一步减少了锁的竞争,并发度大大增加。
并且 JDK 1.7 ConcurrentHashMap 只使用了数组 + 链表的结构,而 JDK 1.8 和 HashMap一样引入了红黑树。
JDK 1.7锁用的是ReentrantLock,具体上锁的方式来源于 Segment,这个类实际继承了 ReentrantLock,因此它自身具备加锁的功能。
1.8 也不借助于 ReentrantLock 了,直接用 synchronized,这也侧面证明,都 1.8 了 synchronized 优化后的速度已经不下于 ReentrantLock 了。
扩容的区别
JDK 1.7 中的扩容:
- 基于 Segment:
ConcurrentHashMap是由多个Segment组成的,每个Segment中包含一个HashMap。当某个Segment内的HashMap达到扩容阈值时,单独为该Segment进行扩容,而不会影响其他Segment。 - 扩容过程:每个
Segment维护自己的负载因子,当Segment中的元素数量超过阈值时,该Segment的HashMap会扩容,整体的ConcurrentHashMap并不是一次性全部扩容。
JDK 1.8 中的扩容:
- 全局扩容:
ConcurrentHashMap取消了Segment,变成了一个全局的数组(类似于HashMap)。因此,当ConcurrentHashMap中任意位置的元素超过阈值时,整个ConcurrentHashMap的数组都会被扩容。 - 基于 CAS 的扩容:在扩容时,
ConcurrentHashMap采用了类似HashMap的方式,但通过CAS 操作确保线程安全,避免了锁住整个数组。在扩容时,多个线程可以同时帮助完成扩容操作。 - 渐进式扩容:JDK 1.8 的
ConcurrentHashMap引入了渐进式扩容机制,扩容时并不是一次性将所有数据重新分配,而是多个线程共同参与,逐步迁移旧数据到新数组中,降低了扩容时的性能开销。