快速认识ClickHouse数据库
...大约 5 分钟ClickHouse数据库
1、OLTP与OLAP
OLTP(Online Transaction Processing)联机事务处理系统
- 对数据的增删改查等操作
- 典型代表有MySQL、Oracle等数据库,对应的网站、系统应用后端数据库
- 存储的是业务数据,来记录某类业务事件的发生,比如下单、支付、注册等等
- 大多数支持事务
- 针对事务进行操作,对响应时间要求高,数据量相对较少
面临的问题
- 针对TP、PB级别的数据,传统的MySQL数据库已经力不从心,尤其是以数据分析这种典型 “全盘” 扫描的统计业务,大规模扫盘已让MySQL不堪重负,为了解决这类问题,从数据应用场景角度分为OLTP与OLAP。
OLAP(Online Analytical Processing)联机分析处理系统
- OLAP支持复杂的分析操作,侧重决策,并且提供直观易懂的查询结果
- 典型代表有ClickHouse、Doris、StarRocks
- 数据量非常大,常规是TB级别的
- 已添加到数据库的数据不擅长修改
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分
- 事务不是必须的
- 对数据一致性要求低
2、ClickHouse基本介绍
- ClickHouse是俄罗斯的Yandex(搜索巨头)于2016年开源的列式存储数据库,使用c++编写,主要用于在线 分析处理查询(OLAP)。
- ClickHouse支持标准的SQL查询语言,并提供了许多常用的查询功能和高级特性,如复杂的聚合函数、窗口函 数和跨表查询等。
- 另外还有一些关键特性,像是列式存储/数据分区与线程并行/支持丰富的表引擎
3、列式存储
示例数据:
| 用户ID | 年龄 | 性别 | 注册日期 |
|---|---|---|---|
| 1 | 25 | M | 2023-01-01 |
| 2 | 30 | F | 2023-01-02 |
| 3 | 25 | M | 2023-01-03 |
| 4 | 35 | M | 2023-01-04 |
| 5 | 30 | F | 2023-01-05 |
行式存储
[1,25,'M','2023-01-01']
[2,30,F',‘2023-01-02']
[3,25,'M','2023-01-03']
[4,35,'M','2023-01-04']
[5,30,'F','2023-01-05']
示例数据:
用户ID列:[1,2,3,4,5]
年龄列:[25,30,25,35,30]
性别列:['M','F','M','M','F']
注册日期列:['2023-01-01','2023-01-02','2023-01-03','2023-01-04','2023-01-05']
列式存储的优点:
不用读取整行,计数,求和等统计操作优于行式存储(比如说,这个数据库中有几名男性)
查询部分列时(因为只取某一列),查询IO量小
同一列数据类型相同,更容易进行数据压缩
RLE/Delta/LZ4/字典压缩等压缩算法
对于性别列[‘M’, ‘F’, ‘M', ’M’, ’F’],可以使用字典压缩算法:
原始数据:['M','F','M','M','F'] 字典:['M':0,F':1] 压缩数据:[1,0,0,11]
由于压缩后数据量更小,所以更节省磁盘空间,同时可以间接提高缓存命中率与网络中传输效率
4、数据分区与线程并行
一、什么是分区?
- 分区就是按照一定的业务逻辑,将数据“分门别类”的整理起来,方便后续的查询和管理
创建表SQL语句
CREATE TABLE test{
`Days` Date,
`Name` String,
`Event` String
}engine=MergeTree()
PARTITION BY (Days) ORDER BY (Name);
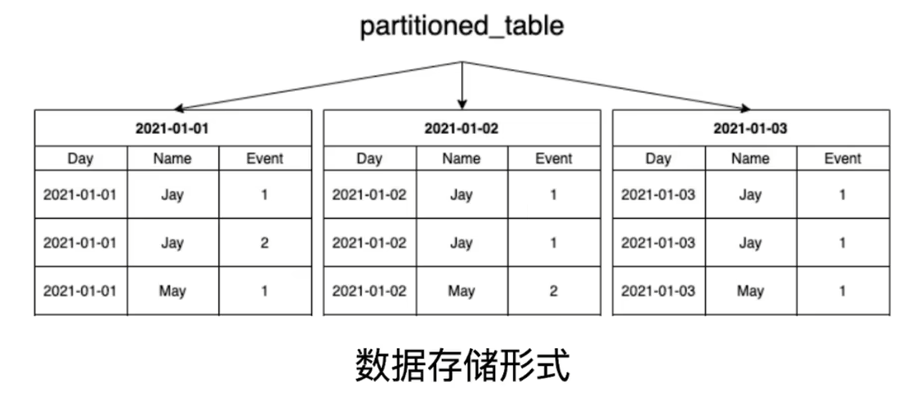
二、线程并行指的是什么?
ClickHouse将数据划分为多个partition,面对涉及跨分区的查询统计,ClickHouse会以分区为单位并行处理
- 优点:在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时
- 缺点:对于单条查询使用多CPU核心,不利于同时并发多条查询。所以对于高QPS的查询业务,ClickHouse并不是强项。
5、支持丰富表引擎
表引擎决定了什么?
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持
- 如何并发数据访问,是否可以执行多线程请求
- 是否存在索引,以及如何使用索引
- 数据复制如何进行复制
有哪些表引擎?
- MergeTree:最常用的,仅持分区,支持TTL
- 日志引擎:具有最小功能的轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。TinyLog./StripeLog/Log
- 集成引擎:用于与其他的数据存储与处理系统集成的引擎。支kafka/MySQL/ODBC/JDBC/HDFS
- 用于其他特定功能的引擎
6、直视其缺点
1.不支持高并发请求
- ClickHouse的查询性能好,指的不是同时对外提供的QPS;而是可以在海量数据中快速进行检索的性能
- ClickHouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行
- 所以ClickHouse.不能支持高并发的使用场景
2.对Update/Delete支持不好
- ClickHouse在数据导入时全部是顺序Append写,写入后数据段不可更改;顺序写的特性即便在机械硬盘 上也有着优异的写入性能。
- 为了支持修改,Clickhouse提供了一套单独的异步机制去操作
3.单个插入性能低
- 每次批量Insert都会生成一个新的Data Part,Data Part就是分区里的一个文件
- 如果每次只插入一条数据,在查询的时候,就会影响查询效率,因为他需要扫描分区内的所有Data Part
7、适用场景
- 数据量大的,数据分析的场景
- 适合作为大宽表,即包含大量列(几百甚至上千列)的表结构,当需要分析海量数据但只涉及少数几列时,性能极高
- 数据批量写入,且数据少更新或不更新
- 无需事务,数据一致性要求低
8、不适用场景
- 不支持事务,不适合作为“业务数据库”
- 不擅长根据主键按行粒度进行查询,故不应该把clickhouse当做key-value数据库使用
- 不擅长频繁的更新和删除数据操作