ShardingSphere
...大约 3 分钟MySQL数据库分库分表
为什么要分库分表?
- 数据量庞大。
- 查询性能缓慢,之前可能是 20ms,后续随着数据量的增长,查询时间呈指数增长。
- 数据库连接不够。
什么是分库分表
分库和分表有两种模式,垂直和水平。 分库两种模式:
- 垂直分库:电商数据库拆分为用户、订单、商品、交易等数据库。
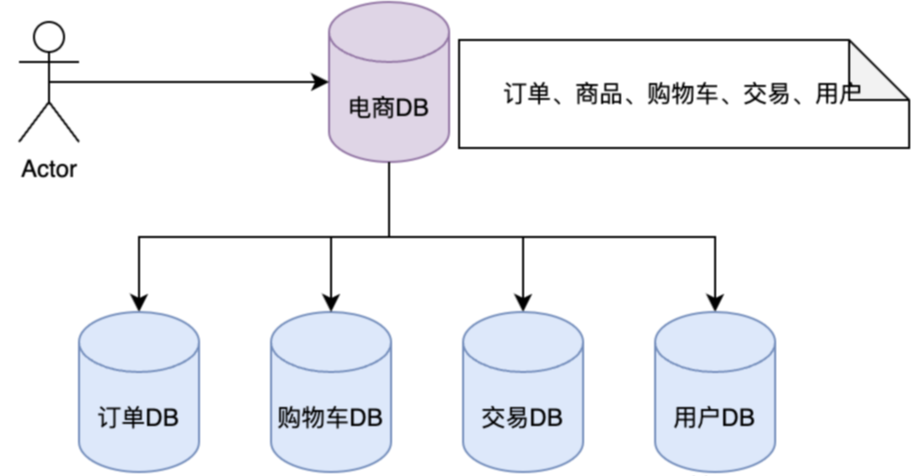
水平分库:用户数据库,拆分为多个,比如User_DB_0 - x。
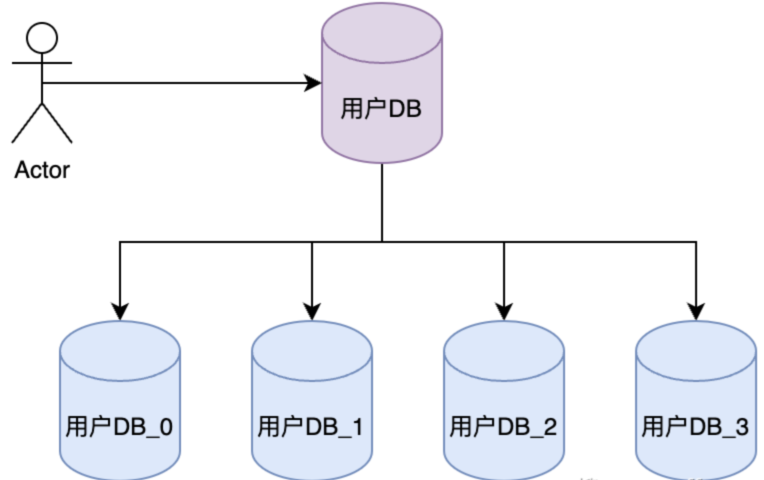
分表两种模式:
垂直分表:将数据库表按照业务维度进行拆分,将不常用的信息放到一个扩展表。
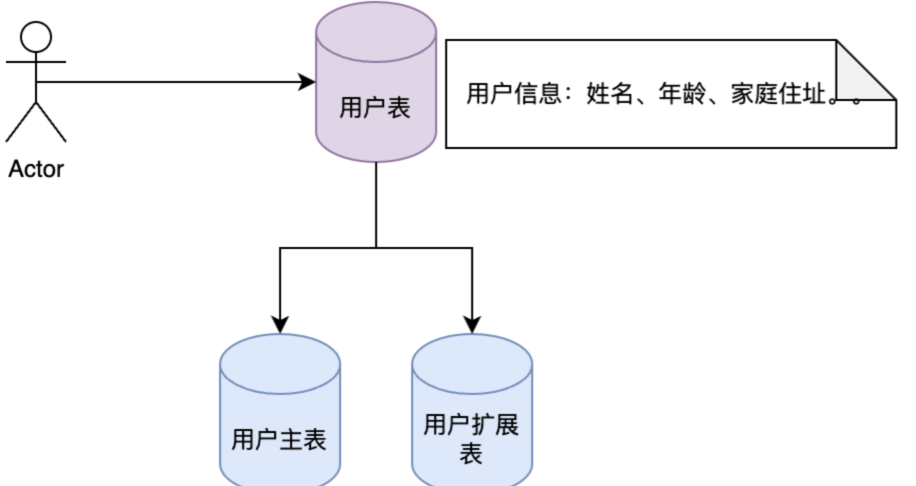
水平分表:将用户表水平拆分,展现形式就是 User_Table_0 - x。
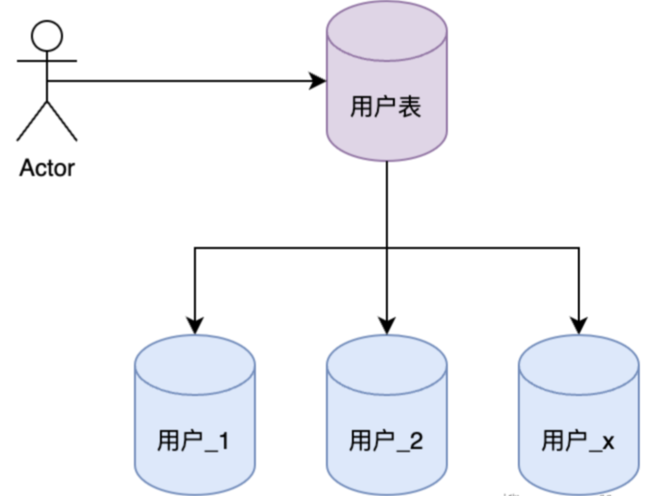
不同场景
1. 什么场景分表?
- 单表的数据量过大。
- 单表存在较高的写入场景,可能引发行锁竞争。
- 当表中包含大量的 TEXT、LONGTEXT 或 BLOB 等大字段。
2. 什么场景分库?
- 当单个数据库支持的连接数已经不足以满足客户端需求。
- 数据量已经超过单个数据库实例的处理能力。
3. 什么场景分库分表?
高并发写入和海量数据
分库分表设计
1. 如何选择分片键?
- 数据均匀性:分片键应该保证数据的均匀分布在各个分片上,避免出现热点数据集中在某个分片上的情况。
- 业务关联性:分片键应该与业务关联紧密,这样可以避免跨分片查询和跨库事务的复杂性。
- 数据不可变:一旦选择了分片键,它应该是不可变的,不能随着业务的变化而频繁修改。
那用户名和用户ID选哪个作为分片键?
- 用户名。用户名可以登录。
2. 分库分表算法?
分库分表的算法会根据业务的不同而变化,所以并没有固定算法。在业界里用的比较多的有两种:
- HashMod:通过对分片键进行哈希取模的分片算法。
- 时间范围: 基于时间范围分片算法。
分片算法讲解一个数据均匀,时间范围并不适合优惠券模板业务,因为商家用户前期比较少,后面会越来越多,所以有比较明显的不均匀问题。*
引入 ShardingSphere-JDBC到项目
1、引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>
2、定义分片规则
spring:
datasource:
# ShardingSphere 对 Driver 自定义,实现分库分表等隐藏逻辑
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
# ShardingSphere 配置文件路径
url: jdbc:shardingsphere:classpath:shardingsphere-config.yaml
shardingsphere-config.yaml
# 数据源集合
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/link?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
- !SHARDING
tables:
t_user:
# 真实数据节点,比如数据库源以及数据库在数据库中真实存在的
actualDataNodes: ds_0.t_user_${0..15}
# 分表策略
tableStrategy:
# 用于单分片键的标准分片场景
standard:
# 分片键
shardingColumn: username
# 分片算法,对应 rules[0].shardingAlgorithms
shardingAlgorithmName: user_table_hash_mod
# 分片算法
shardingAlgorithms:
# 数据表分片算法
user_table_hash_mod:
# 根据分片键 Hash 分片
type: HASH_MOD
# 分片数量
props:
sharding-count: 16
# 展现逻辑 SQL & 真实 SQL
props:
sql-show: true
ShardingSphere 数据分片核心概念
1、逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。
2、真实表
在水平拆分的数据库中真实存在的物理表。
比如说:
逻辑表是t_user,应用程序中操作的表名,数据库中不是真实存在的,使应用认为只是与单一表交互。
真实表,t_user_0到t_user_15,是数据库真实存在的