一条sql的执行流程
...大约 3 分钟MySQL数据库
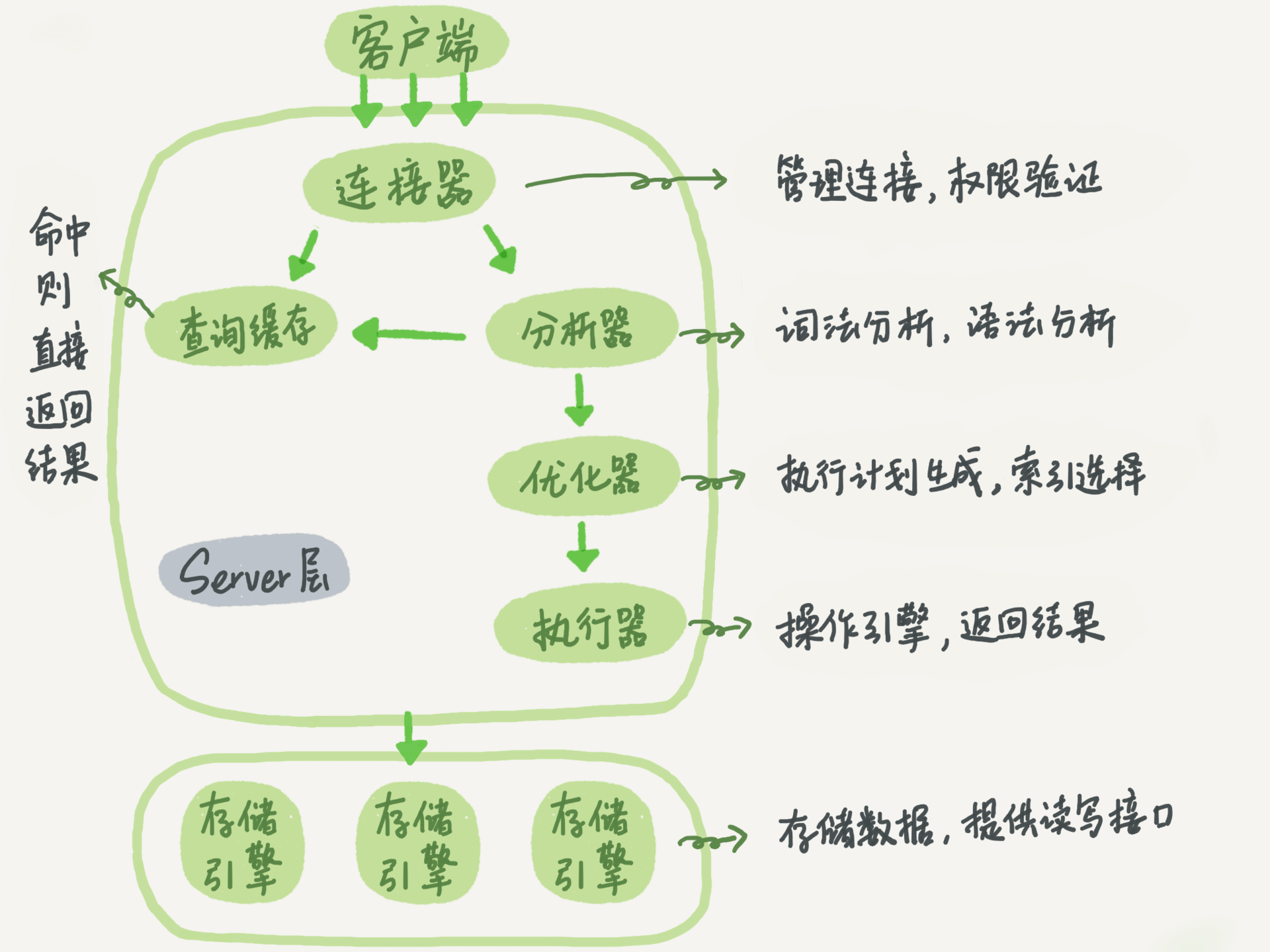
首先客户端通过连接器和mysql相连,连接器用来验证连接,维持连接和管理连接,如果是一条查询语句,首先还会查询缓存,但是任何的更新操作都会导致缓存失效。效率的提升并不高,所以这个功能一般都被我们给关闭了。8.0之后直接就被弃用了。
接着还会进行词法分析和语法分析,这和java的前端编译差不多,一般一个语句如果错了,那在这个阶段就能看到这样的提示
mysql> elect * from t where ID=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
优化器是一个重头戏,选出最适合的查询索引连接顺序等,并且在这个阶段还会生成具体的执行计划
具体如下:
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。优化器的作用是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
比如你执行下面这样的语句,这个语句是执行两个表的 join:
mysql> select * from t1 join t2 using(department_id) where t1.c=10 and t2.d=20;
- 既可以先从表 t1 里面取出
c=10的记录的 department_id值,再根据 department_id值关联到表 t2,再判断 t2 里面d的值是否等于 20。 - 也可以先从表 t2 里面取出
d=20的记录的 department_id值,再根据 department_id值关联到 t1,再判断 t1 里面c的值是否等于 10。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
可能这么判断:如果表t1比较小,那么就先用第一个,反之用第二个。
执行器就会根据执行计划无脑的操作就好了
mysql的存储引擎是一个可插拔的设计,可以用InnoDB,也可以用MyISAM,server层统一定义了一套api,不同的存储引擎一一的去实现就好了,比如这样一条查询语句:
select * from T where ID=10;
执行器就会:
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。