Redis基础
什么是Redis?
Rdis是一种基于内存的NoSQL 数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。基于键值对(key-value)进行存储。
Redis提供了多种数据类型来支持不同的业务场景,比如String(字符串)、Hash(哈希)、List(列表)、Set(集 合)、Zset(有序集合)、Bitmaps(位图)、HyperLogLog(基数统计)、GEO(地理信息)、Stream(流), 并且对数据类型的操作都是原子性的,因为执行命令由单线程负责的,不存在并发竞争的问题。
除此之外,Redis还支持事务、持久化、Lua脚本、多种集群方案(主从复制模式、哨兵模式、切片机群 模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等。
Redis 常见的数据类型?
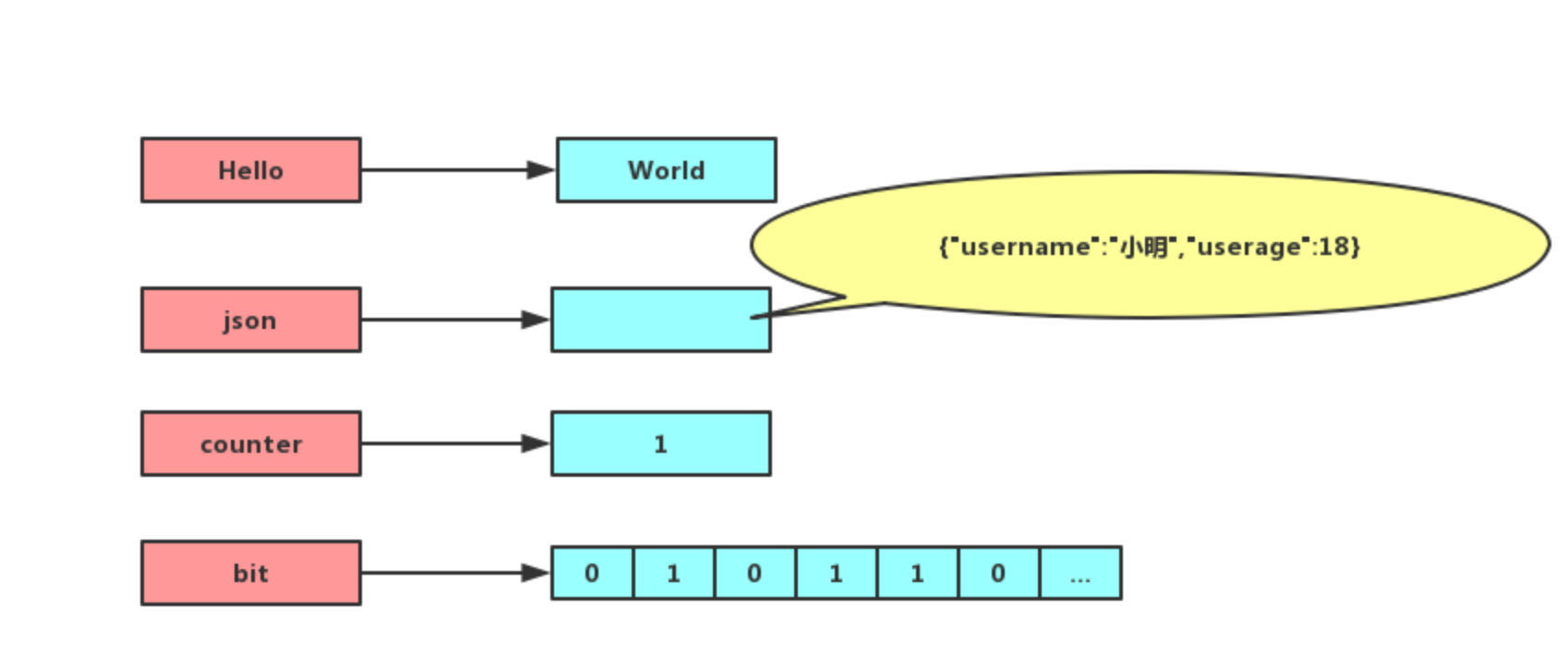
①、String
- 字符串(简单的字符串、复杂的字符串(例如 JSON、XML))
- 数字 (整数、浮点数)
- 甚至是二进制(图片、音频、视频),但最大不能超过 512MB
②、Hash
键值对集合,key 是字符串,value 是一个 Map 集合,比如说 value = {name: '秦一', age: 30},name 和 age 属于字段 field,秦一 和 30 属于值 value。
哈希主要有以下两个典型应用场景:
- 缓存用户信息
- 缓存对象
什么使用 hash 类型而不使用 string 类型序列化存储?
感受一下:
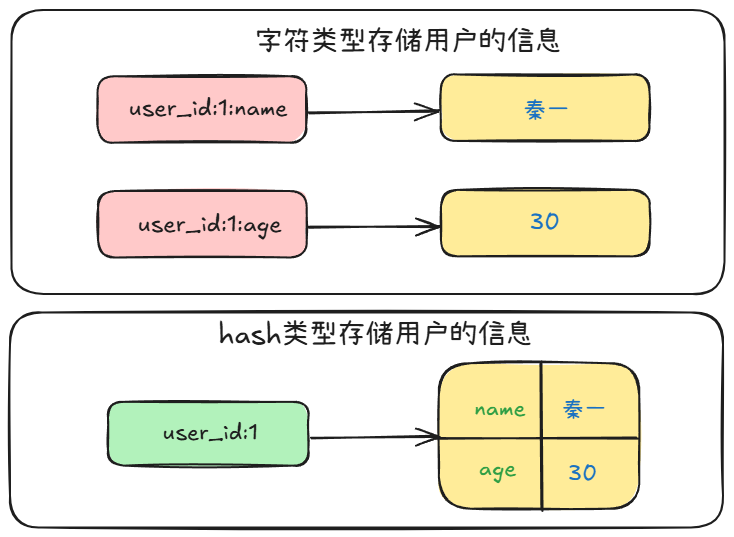
可以看得出,使用 hash 比使用 string 更便于进行序列化,我们可以将一整个用户对象序列化,然后作为一个 value 存储在 Redis 中,存取更加便捷。
③、List
顺序插入列表
主要有以下两个使用场景:
- 消息队列
- 博客、新闻、论坛的最新文章流,保证最新文章在最前面
④、 BitMap
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset).定位元素。BitMapi通过 最小的单位bt来进行1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于bit是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统 计的场景。

比如说:
签到统计
在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用1个bt位就能表示,一个月(假设是31天)的签到情况用31个 bt位就可以,而一年的签到也只需要用365个bt位,根本不用太复杂的集合类型。
假设我们要统计D100的用户在2022年6月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户6月3号已签到。
SETBIT uid:sign:100:202206 2 1
第二步,检查该用户 6 月 3 日是否签到。
GETBIT uid:sign:100:202206 2
第三步,统计该用户在 6 月份的签到次数。
BITCOUNT uid:sign:100:202206
这样,我们就知道该用户在 6 月份的签到情况了。
如何统计这个月首次打卡时间呢?
Redis提供了BITPOS key bitValue[start][end]指令,返回数据表示Bitmap中第一个值为bitValue 的offset位置。
在默认情况下,命令将检测整个位图,用户可以通过可选的start参数和end参数指定要检测的范 围。所以我们可以通过执行这条命令来获取usrD=100在2022年6月份首次打卡日期:
BITPOS uid:sign:100:202206 1
需要注意的是,因为 offset 从 0 开始的,所以我们需要将返回的 value + 1 。
⑤、Stream
redis的消息队列,之前做过一个项目,其中消息就是用的Stream,没有用RocketMQ。
什么是 I/O 多路复用?
IO 多路复用是指在单线程中同时监控多个文件描述符(fd),一旦某个文件描述符就绪,就立即处理对应的事件。能够在没有阻塞的情况下高效地处理大量并发连接,实现高并发的 IO 操作。
常见的 I/O 多路复用机制包括 select、poll 和 epoll 等。
比如说你是一名数学老师,上课时提出了一个问题:“今天谁来证明一下勾股定律?”
同学小王举手,你就让小王回答;小李举手,你就让小李回答;小张举手,你就让小张回答。
这种模式就是 IO 多路复用,你只需要在讲台上等,谁举手谁回答,不需要一个一个去问。
Redis 就是使用 epoll 这样的 I/O 多路复用机制,在单线程模型下实现高效的网络 I/O,从而支持高并发的请求处理。
举例子说一下 I/O 多路复用
假设你是一个老师,让 30 个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
- 第一种选择:按顺序逐个检查,先检查 A,然后是 B,之后是 C、D。。。这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理 socket,根本不具有并发能力。
- 第二种选择:你创建 30 个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
- 第三种选择,你站在讲台上等,谁解答完谁举手。这时 C、D 举手,表示他们解答问题完毕,你下去依次检查 C、D 的答案,然后继续回到讲台上等。此时 E、A 又举手,然后去处理 E 和 A。
第一种就是阻塞 IO 模型,第三种就是 I/O 复用模型。
Linux 系统有三种方式实现 IO 多路复用:select、poll 和 epoll。
select—— “不断喊号的大堂服务员”,每隔几秒钟,就大声喊一遍:“有没有人准备好点餐?”你最多只能处理 1024 桌(系统的
FD_SETSIZE限制)。人多的时候,你光是走来走去问话就要花掉大部分时间,效率低下。
遍历所有 socket
需要不断调用
select
poll—— “拿着顾客名单逐个问”,换了一种方式,不再大声喊,而是拿着一个顾客名单,逐一走过去询问:“请问你准备好点餐了吗?”,你可以处理更多桌的顾客,不受 1024 的限制,但你每次还是得一个个地问。- 解决了
select的数量限制(支持更多的顾客)。 - 每次询问仍然需要遍历所有的顾客,如果 99 桌顾客都没准备好,你还是得白跑一趟。
- 遍历所有 socket
- 需要不断调用
poll
- 解决了
epoll—— “顾客举手示意服务员”- 只有需要点单的顾客才会通知你,避免了不必要的询问,提高了效率。
- 只处理活跃 socket
- 只在有事件时
epoll_wait才触发
Redis 为什么快呢?
①、基于内存的数据存储,Redis 将数据存储在内存当中,没有磁盘的io操作
②、单线程模型,这意味着在任何时刻只有一个命令在执行。这样就避免了线程切换和锁竞争带来的消耗。
③、IO 多路复⽤,基于 Linux 的 select/epoll 机制。处理大量客户端的 Socket 请求,内核会一直监听这些Socket上的连接请求或者数据请求,一旦有请求到达,就会交给 Redis 处理,因为这是基于非阻塞的 I/O 模型,这就让 Redis 可以高效地进行网络通信,I/O 的读写流程也不再阻塞。就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求。
④、高效的数据结构
比如说String采用SDS简单动态字符串
| 操作 | C 语言 char* | Redis SDS |
|---|---|---|
| 计算长度 | O(n) | O(1) |
| 追加字符串 | 可能需要 malloc | 可能不会 malloc(因为有 free 预分配) |
| 删除字符串 | 立即释放 | 惰性释放,减少碎片化 |
hash采用哈希表,能够动态扩容,还采用链地址法
压缩列表(ZipList),当哈希表或列表数据量较小时,Redis 不会使用哈希表或链表,而是使用压缩列表来节省内存。
采用跳表(Skip List),查询更快,也适合范围查询,相比于红黑树,跳表的范围查询更简单高效。
Redis 可以用来干什么?
- 缓存,Token 、验证码、分布式锁的存储,对省市区数据的缓存
- 计数器,天然支持计数功能,而且计数性能非常好,可以用来记录浏览量、点赞、登录失败次数计数等等
- 排行榜,Zset,实时展示用户的活跃度。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、粉丝、共同好友/喜好
- 消息队列,提供了发布订阅功能和阻塞队列的功能
- 分布式锁,电商项目中,用户注册、超卖、秒杀
Redis 常用命令
①、操作字符串的命令有:SET key value,get,del,incr key,decr key
②、操作列表的命令有:LPUSH, RPUSH, LPOP, RPOP, LRANGE key start stop
③、操作集合的命令有:SADD,SREM,SMEMBERS
④、操作哈希的命令有:HSET,HSET
为什么 Redis 不使用 B+ Tree 作为存储数据结构?
Redis 主要设计为内存存储系统,B+ Tree 更适合磁盘存储系统,因为它可以减少磁盘I/O操作。Redis优先考虑的是访问速度和内存效率。
Redis 网络 IO 模型用的是什么?
使用非阻塞IO和IO多路复用技术。
简而言之,非阻塞I/O让程序不必等待一个操作完成才能继续做其他事,而I/O多路复用让程序能同时监控多个操作,一旦有操作完成就立刻处理,这两种技术都是为了让程序运行得更高效
在技术上,这意味着Redis可以使用一个进程(服务员)来同时监控多个网络连接(顾客),并且只关注那些"举手"(即准备好进行数据交换的连接)。这让Redis能够非常高效地处理成千上万的连接,而不需要为每个连接分配单独的资源或服务员。