Redis运维
...大约 4 分钟Redis
Redis 报内存不足怎么处理?
Redis 内存不足有这么几种处理方式:
- 修改配置文件 redis.conf 的 maxmemory 参数,增加 Redis 可用内存
- 也可以通过命令 set maxmemory 动态设置内存上限
- 修改内存淘汰策略,及时释放内存空间
- 使用 Redis 集群模式,进行横向扩容。
Redis key 过期策略有哪些我?
惰性删除和定期删除。
惰性删除:当某个键被访问时,如果发现它已经过期,Redis 会立即删除该键;但这也意味着如果一个已过期的键从未被访问,它就不会被删除,会占用额外的内存空间。
定期删除:每隔一段时间,Redis 就会随机检查一些键是否过期,如果过期就删除。
内存淘汰策略?
- noeviction:默认策略,不进行任何数据淘汰,直接返回错误信息。
- allkeys-lru:从所有键中,使用 LRU 算法淘汰最近最少使用的键。
- allkeys-lfu:从所有键中,使用 LFU 算法淘汰最少使用的键。
- volatile-lru:从设置了过期时间的键中淘汰最近最少使用的键。
- volatile-ttl:从设置了过期时间的键中淘汰即将过期的键。
LRU 和 LFU 的区别是什么?
LRU(Least Recently Used):基于时间维度,淘汰最近最少访问的键。适合访问具有时间特性的场景。
LFU(Least Frequently Used):基于次数维度,淘汰访问频率最低的键。更适合长期热点数据场景。
大 key 问题
"big Key"是指一个内存空间占用比较大的键(Key)
- 内存压力,内存分布不均。在集群模式下,不同slot分配到不同实例中,如果大ky都映射到一个实例,则分布不均,查询效率也会受到影响。
- 由于Redis单线程执行命令,操作大Key时耗时较长,从而导致Redis出现其它命令阻塞的问题。
- 大key对资源的占用巨大,在你进行网络I/O传输的时候,导致你获取过程中产生的网络流量较大,从而产生网络传输时间延长甚至网络传输发现阻塞的现象,例如一个key 2MB,请求个1000次2000MB。
- 客户端超时。因为操作大key时耗时较长,可能导致客户端等待超时。
如何找到大 key?
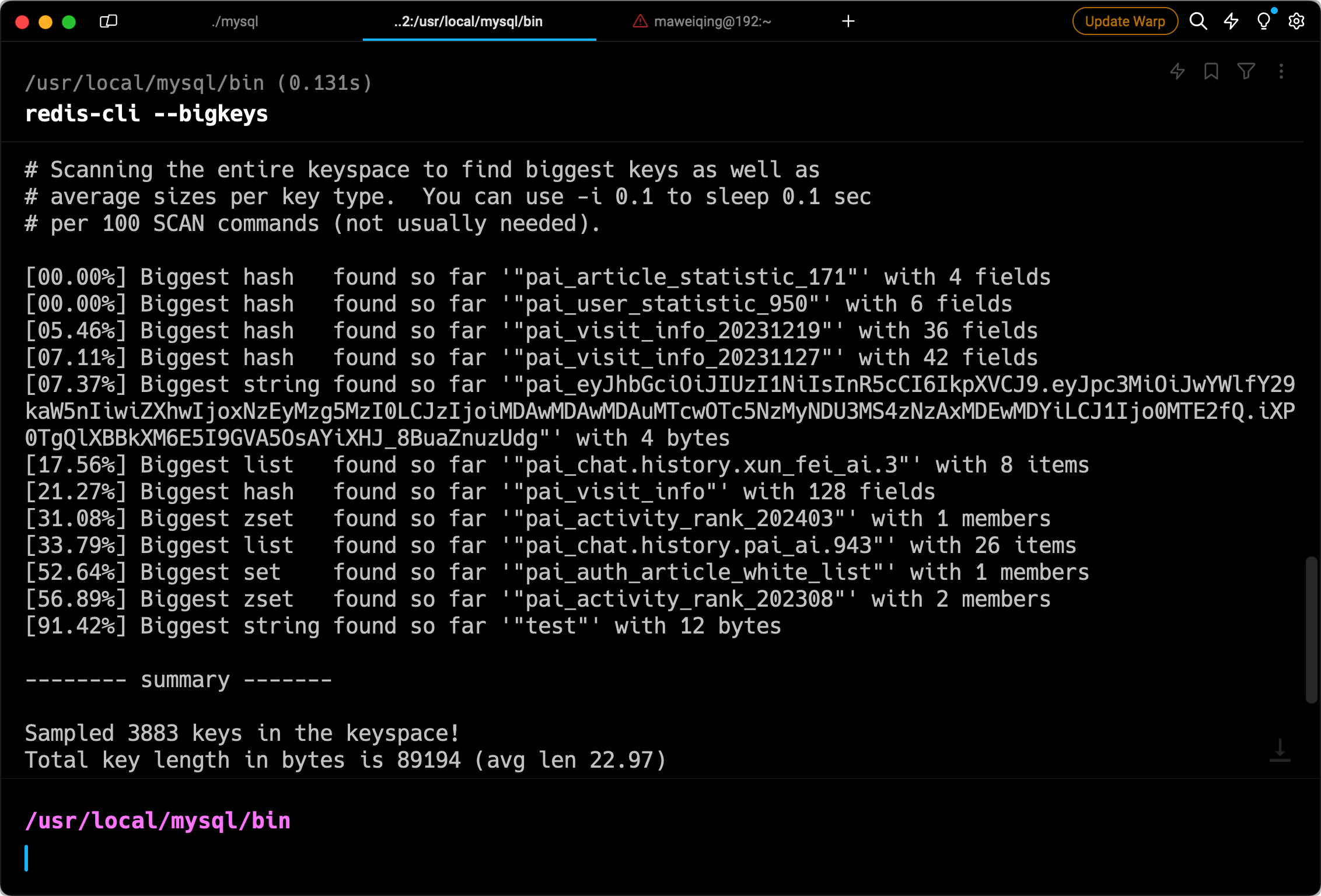
①、bigkeys 参数:使用 bigkeys 命令以遍历的方式分析 Redis 实例中的所有 Key,并返回整体统计信息与每个数据类型中 Top1 的大 Key
bigkeys 命令的使用:
redis-cli --bigkeys
②、redis-rdb-tools:redis-rdb-tools 是由 Python 语言编写的用来分析 Redis 中 rdb 快照文件的工具。
源码地址:https://github.com/sripathikrishnan/redis-rdb-tools/
怎么解决:
- 大key→小key,对于数据过大的
ZSet可以分页查询 - 定期清理大 Key,对于不重要的大 Key,可以设置较短的过期时间;删除大 Key 时,使用使用
UNLINK异步删除,而不是DEL - 搭建redis集群,把key分配到不同的hash slot槽所在的分片上
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
数据key不是与节点绑定,而是与插槽绑定
插槽可以集体转换,它与节点是绑定的关系,节点宕机了,还可以将插槽绑定到到别的节点上;如果和节点绑定的话,节点宕机了,你还得重新配置节点或手动迁移大量数据;
为什么Redis要选择单线程
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣